2022-07-09, 18:47
Der folgende Trick hat mir einige Klimmzüge erspart. In einer Textdatei gab es an diversen Stellen mehrfache Leerzeichen, die ich durch ein einzelnes ersetzen wollte.
Ich hätte jetzt einfach so lange doppelte Leerzeichen durch ein einzelnes ersetzen können, bis keine doppelten Leerzeichen mehr vorhanden sind, über einen regular expression geht es aber viel eleganter.
import re
s = 'a b c'
print(re.sub('\s+',' ',s)) |
import re
s = 'a b c'
print(re.sub('\s+',' ',s))
2022-06-27, 21:02
Ich hatte vor kurzem das Problem (oder die „Challenge“), einen sehr komplexen Cognos-Report anpassen zu müssen. In mehreren dutzend Formeln mussten Formeln angepasst werden, den Formel-Check zur Prüfung meiner Anpassungen konnte ich jedoch nicht nutzen, da die Datenüberprüfung unendlich lang gedauert hätte (schlechtes Report-Design…).
Mit Python gab es aber eine einfache und elegante Lösung, die mit dem Export des Report-Designs in eine XML-Datei begann.
In der XML-Datei fanden sich dann Schnipsel wie
<expression>abs(total((if ([Database].[storedProc].[ColumnID]=6) then ([Database].[storedProc].[Amount]) else (0))))</expression>
Mit dem folgenden Programm-Code konnte ich dann innerhalb der expression-Tags einfach die öffnenden und schließenden Klammern zählen. Wenn die Zahl der öffnenden Klammern nicht der Zahl der schließenden Klammern entsprach, war die Formel noch falsch.
import re
buffer = open('./Report.xml','r').read()
results = re.findall(r"(<expression>)(.*)(</expression>)",buffer,re.MULTILINE)
for result in results:
expression = result[1]
opened = expression.count('(')
closed = expression.count(')')
if opened != closed:
print(expression) |
import re
buffer = open('./Report.xml','r').read()
results = re.findall(r"(<expression>)(.*)(</expression>)",buffer,re.MULTILINE)
for result in results:
expression = result[1]
opened = expression.count('(')
closed = expression.count(')')
if opened != closed:
print(expression)
2022-06-27, 20:47
Nehmen wir mal an, wir haben eine Excel-Datei Daten.xlsx mit Namen, in der es Fehleingaben durch beispielsweise einen Buchstabendreher geben kann:
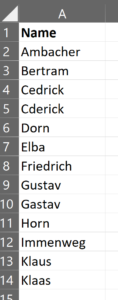
Mit Python und dem Levenshtein-Paket können wir die Ähnlichkeit der Namen recht einfach prüfen.
import pandas as pd
import Levenshtein
df = pd.read_excel('Daten.xlsx')
df = df.sort_values(by=['Name'])
df = df.reset_index(drop=True)
dfs= df.shift() # Shift df by one row
dfs = dfs.rename(columns={'Name': 'Nameshifted'})
df_combined = pd.concat([df,dfs],axis=1) # combine original and shifted df
df_combined = df_combined.fillna('') # remove NaNs
for index, row in df_combined.iterrows():
df_combined.loc[index,'Ratio'] = (Levenshtein.ratio(row['Name'], row['Nameshifted']))
df_combined.loc[index,'Distance'] = (Levenshtein.distance(row['Name'], row['Nameshifted']))
print(df_combined) |
import pandas as pd
import Levenshtein
df = pd.read_excel('Daten.xlsx')
df = df.sort_values(by=['Name'])
df = df.reset_index(drop=True)
dfs= df.shift() # Shift df by one row
dfs = dfs.rename(columns={'Name': 'Nameshifted'})
df_combined = pd.concat([df,dfs],axis=1) # combine original and shifted df
df_combined = df_combined.fillna('') # remove NaNs
for index, row in df_combined.iterrows():
df_combined.loc[index,'Ratio'] = (Levenshtein.ratio(row['Name'], row['Nameshifted']))
df_combined.loc[index,'Distance'] = (Levenshtein.distance(row['Name'], row['Nameshifted']))
print(df_combined)
Als Ergebnis erhält man dann einen Dataframe, der die sortierten Namen miteinander vergleicht und die Levenshtein-Ratio sowie die Levenshtein-Distanz ausgibt.
|
Name |
Nameshifted |
Ratio |
Distance |
| 0 |
Ambacher |
|
0.000000 |
8.0 |
| 1 |
Bertram |
Ambacher |
0.266667 |
8.0 |
| 2 |
Cderick |
Bertram |
0.285714 |
6.0 |
| 3 |
Cedrick |
Cderick |
0.857143 |
2.0 |
| 4 |
Dorn |
Cedrick |
0.181818 |
6.0 |
| 5 |
Elba |
Dorn |
0.000000 |
4.0 |
| 6 |
Friedrich |
Elba |
0.000000 |
9.0 |
| 7 |
Gastav |
Friedrich |
0.000000 |
9.0 |
| 8 |
Gustav |
Gastav |
0.833333 |
1.0 |
| 9 |
Horn |
Gustav |
0.000000 |
6.0 |
| 10 |
Immenweg |
Horn |
0.166667 |
7.0 |
| 11 |
Klaas |
Immenweg |
0.000000 |
8.0 |
| 12 |
Klaus |
Klaas |
0.800000 |
1.0 |
Bei hoher Ratio oder kleiner Distanz sollte man sich die Werte anschauen.
Hinweis: Ich bin hier davon ausgegangen, dass nur im Namen der nächsten Zeile ein Dreher auftreten kann. Vergleicht man alle n Namen mit allen anderen n-1 Namen, so wird es schnell aufwändig und zeitintensiv.
2022-06-27, 20:22
Hier die Folien meines MyTinyTodo2LaTeX Lightning Talks, gehalten auf der Sommertagung 2022 von Dante e.V. in Magdeburg.
Folien
Schlagwörter:
LaTeX,
Export,
MyTinyTodo Category:
LaTeX,
Artikel |
Kommentare deaktiviert für Folien meines „MyTinyTodo“-Vortrags bei der Dante Sommertagung in Magdeburg
2022-06-27, 20:20
Hier die Folien meines „Beamer Themes“-Vortrags bei der Dante Sommertagung in Magdeburg.
FolienFolien
Schlagwörter:
Beamer,
List,
Themes Category:
LaTeX,
Artikel |
Kommentare deaktiviert für Folien meines „Beamer Themes“-Vortrags bei der Dante Sommertagung in Magdeburg
2022-06-27, 20:12
Unter https://github.com/UweZiegenhagen/LaTeX-Beamer-Theme-Overview habe ich ein Projekt begonnen, das alle in einem TeX Live vorhandenen Beamer-Themes anhand von Beispielbildern vorstellt.
Direkter Link zur Übersicht: https://github.com/UweZiegenhagen/LaTeX-Beamer-Theme-Overview/blob/main/OVERVIEW.md
Technisch funktioniert es so, dass der Name des Themes aus dem Dateinamen extrahiert wird, dazu nutze ich mein Varsfromjobname-Paket. Die einzelnen PDFs werden dann über ein Python-Skript mit LaTeX erzeugt, mittels imagemagick in einzelne PNGs zerlegt und in der Overview.md verlinkt.
Hinweis: Nicht bei allen in TeX Live vorhandenen Themes funktioniert dieser Weg, die Autoren der nicht funktionierenden Themes werde ich anschreiben.
Category:
LaTeX,
Artikel |
Kommentare deaktiviert für Liste aller Beamer Themes in TeX Live
2022-06-27, 20:10
Die Helligkeit des Bildschirms lässt sich auch recht einfach per Powershell setzen
powershell (Get-WmiObject -Namespace root/WMI -Class WmiMonitorBrightnessMethods).WmiSetBrightness(1,50) |
powershell (Get-WmiObject -Namespace root/WMI -Class WmiMonitorBrightnessMethods).WmiSetBrightness(1,50)
setzt die Helligkeit beispielsweise auf 50 Prozent.
2022-06-27, 20:06
Für LuaLaTeX gibt es mit showhyphenation und showkerning zwei interessante Pakete, die die möglichen Trennstellen bzw. das Kerning anzeigen.
%!TEX TS-program = lualatex
\documentclass[12pt,ngerman]{scrartcl}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{babel}
\usepackage{blindtext}
\usepackage{microtype}
\usepackage{showhyphenation}
\usepackage[ontop]{showkerning}
\begin{document}
\blindtext
\blindtext
\end{document} |
%!TEX TS-program = lualatex
\documentclass[12pt,ngerman]{scrartcl}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{babel}
\usepackage{blindtext}
\usepackage{microtype}
\usepackage{showhyphenation}
\usepackage[ontop]{showkerning}
\begin{document}
\blindtext
\blindtext
\end{document}

2022-03-20, 22:41
Über eine Verknüpfung auf die Rundll32.exe kann man flink in den Energiesparmodus von Windows wechseln.
In irgendeinem Ordner (z.B. auf dem Desktop) rechte Maustaste => neu => Verknüpfung. Als Speicherort des Elements dann folgendes eingeben:
C:\Windows\System32\rundll32.exe powrprof.dll,SetSuspendState