2022-06-27, 20:47
Nehmen wir mal an, wir haben eine Excel-Datei Daten.xlsx mit Namen, in der es Fehleingaben durch beispielsweise einen Buchstabendreher geben kann:
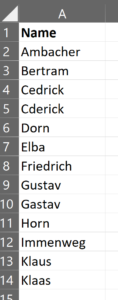
Mit Python und dem Levenshtein-Paket können wir die Ähnlichkeit der Namen recht einfach prüfen.
import pandas as pd
import Levenshtein
df = pd.read_excel('Daten.xlsx')
df = df.sort_values(by=['Name'])
df = df.reset_index(drop=True)
dfs= df.shift() # Shift df by one row
dfs = dfs.rename(columns={'Name': 'Nameshifted'})
df_combined = pd.concat([df,dfs],axis=1) # combine original and shifted df
df_combined = df_combined.fillna('') # remove NaNs
for index, row in df_combined.iterrows():
df_combined.loc[index,'Ratio'] = (Levenshtein.ratio(row['Name'], row['Nameshifted']))
df_combined.loc[index,'Distance'] = (Levenshtein.distance(row['Name'], row['Nameshifted']))
print(df_combined) |
import pandas as pd
import Levenshtein
df = pd.read_excel('Daten.xlsx')
df = df.sort_values(by=['Name'])
df = df.reset_index(drop=True)
dfs= df.shift() # Shift df by one row
dfs = dfs.rename(columns={'Name': 'Nameshifted'})
df_combined = pd.concat([df,dfs],axis=1) # combine original and shifted df
df_combined = df_combined.fillna('') # remove NaNs
for index, row in df_combined.iterrows():
df_combined.loc[index,'Ratio'] = (Levenshtein.ratio(row['Name'], row['Nameshifted']))
df_combined.loc[index,'Distance'] = (Levenshtein.distance(row['Name'], row['Nameshifted']))
print(df_combined)
Als Ergebnis erhält man dann einen Dataframe, der die sortierten Namen miteinander vergleicht und die Levenshtein-Ratio sowie die Levenshtein-Distanz ausgibt.
|
Name |
Nameshifted |
Ratio |
Distance |
| 0 |
Ambacher |
|
0.000000 |
8.0 |
| 1 |
Bertram |
Ambacher |
0.266667 |
8.0 |
| 2 |
Cderick |
Bertram |
0.285714 |
6.0 |
| 3 |
Cedrick |
Cderick |
0.857143 |
2.0 |
| 4 |
Dorn |
Cedrick |
0.181818 |
6.0 |
| 5 |
Elba |
Dorn |
0.000000 |
4.0 |
| 6 |
Friedrich |
Elba |
0.000000 |
9.0 |
| 7 |
Gastav |
Friedrich |
0.000000 |
9.0 |
| 8 |
Gustav |
Gastav |
0.833333 |
1.0 |
| 9 |
Horn |
Gustav |
0.000000 |
6.0 |
| 10 |
Immenweg |
Horn |
0.166667 |
7.0 |
| 11 |
Klaas |
Immenweg |
0.000000 |
8.0 |
| 12 |
Klaus |
Klaas |
0.800000 |
1.0 |
Bei hoher Ratio oder kleiner Distanz sollte man sich die Werte anschauen.
Hinweis: Ich bin hier davon ausgegangen, dass nur im Namen der nächsten Zeile ein Dreher auftreten kann. Vergleicht man alle n Namen mit allen anderen n-1 Namen, so wird es schnell aufwändig und zeitintensiv.
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2020-06-06, 17:33
Für eine Anwendung habe ich eine Möglichkeit gesucht, die „passendste“ Datei in einem Verzeichnis zu suchen. Dies kann relevant sein, wenn die Anwendung eine bestimmte Datei in einem Verzeichnis erwartet, die aber leicht anders benannt wurde als es die Vorgabe erfordert.
Das folgende Beispielprogramm nutzt die Levenshtein-Funktionen der fuzzywuzzy Bibliothek, um die Datei zu finden, die das größte Maß an Gleichheit zum Muster besitzt.
Man kann natürlich auch RegExps benutzen, mit der fuzzywuzzy Bibliothek ist es aber auch recht intuitiv.
# -*- coding: utf-8 -*-
import os
from fuzzywuzzy import fuzz
def guess_file(template, path):
max_ratio = 0
file_max_ratio = ''
for file in os.listdir(path):
file_wo_suffix = os.path.splitext(file)[0]
ratio = fuzz.ratio(file_wo_suffix, template)
if ratio > max_ratio:
max_ratio = ratio
file_max_ratio = file
return(file_max_ratio, max_ratio)
print(guess_file('Meine Inputdaten','R:/')) |
# -*- coding: utf-8 -*-
import os
from fuzzywuzzy import fuzz
def guess_file(template, path):
max_ratio = 0
file_max_ratio = ''
for file in os.listdir(path):
file_wo_suffix = os.path.splitext(file)[0]
ratio = fuzz.ratio(file_wo_suffix, template)
if ratio > max_ratio:
max_ratio = ratio
file_max_ratio = file
return(file_max_ratio, max_ratio)
print(guess_file('Meine Inputdaten','R:/'))
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2011-02-28, 05:52
Mit RecordLinkagegibt es eine R Bibliothek, die den Levenshtein Algorithmus per DLL/SO bereitstellt. Hier ein Beispiel:
library("RecordLinkage")
# the absolute value of the Levenshtein distance
levenshteinDist("Uwe", "uwe")
# a similarity measure
# based on 1 - d(str1,str2) / max(A,B)
# with d as L. distance
# and A, B as lengths of strings
levenshteinSim("Uwe", "uwe")
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
Schlagwörter:
Levenshtein Category:
R |
Kommentare deaktiviert für Levenshtein mit R und der RecordLinkage Bibliothek