2024-01-13, 15:53
Mi dem pylualatex Paket gibt es eine neue Möglichkeit, Python und LaTeX miteinander zu „verheiraten“. Das Besondere an diesem Paket ist, dass es keine zwei Durchläufe benötigt, sondern nur einen einzigen.
%!TEX TS-program = Arara
% arara: lualatex: {shell: yes}
\documentclass{article}
\usepackage[executable=python.exe,localimports=false]{pyluatex}
\begin{document}
\py{2**2**2}
\end{document} |
%!TEX TS-program = Arara
% arara: lualatex: {shell: yes}
\documentclass{article}
\usepackage[executable=python.exe,localimports=false]{pyluatex}
\begin{document}
\py{2**2**2}
\end{document}
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
Schlagwörter:
Python,
LuaLaTeX Category:
LaTeX,
Pakete |
Kommentare deaktiviert für Python und LaTeX in einem Lauf kombinieren mit pylualatex
2024-01-13, 11:14
Neben dem Download von Dateien klappt auch der Upload von Dateien problemlos.
import os
import paramiko
# Replace these variables with your specific values
host = '192.168.0.22'
port = 22
username = '<user>'
private_key_path = 'keyfile'
remote_directory_path = '/home/uwe/uploadtest'
local_directory_path = 'E:/uploadtest'
# Establish an SSH transport session
private_key = paramiko.RSAKey(filename=private_key_path)
transport = paramiko.Transport((host, port))
transport.connect(username=username, pkey=private_key)
# Create an SFTP client
sftp = paramiko.SFTPClient.from_transport(transport)
try:
# Iterate through local files in the specified folder
for local_file in os.listdir(local_directory_path):
local_file_path = os.path.join(local_directory_path, local_file)
# Check if the file is a CSV file
if os.path.isfile(local_file_path): # and local_file.lower().endswith('.csv'):
remote_file_path = os.path.join(remote_directory_path, local_file)
# Upload the CSV file
sftp.put(local_file_path, remote_file_path)
print(f"Uploaded: {local_file} to {remote_file_path}")
finally:
# Close the SFTP session and SSH transport
sftp.close()
transport.close() |
import os
import paramiko
# Replace these variables with your specific values
host = '192.168.0.22'
port = 22
username = '<user>'
private_key_path = 'keyfile'
remote_directory_path = '/home/uwe/uploadtest'
local_directory_path = 'E:/uploadtest'
# Establish an SSH transport session
private_key = paramiko.RSAKey(filename=private_key_path)
transport = paramiko.Transport((host, port))
transport.connect(username=username, pkey=private_key)
# Create an SFTP client
sftp = paramiko.SFTPClient.from_transport(transport)
try:
# Iterate through local files in the specified folder
for local_file in os.listdir(local_directory_path):
local_file_path = os.path.join(local_directory_path, local_file)
# Check if the file is a CSV file
if os.path.isfile(local_file_path): # and local_file.lower().endswith('.csv'):
remote_file_path = os.path.join(remote_directory_path, local_file)
# Upload the CSV file
sftp.put(local_file_path, remote_file_path)
print(f"Uploaded: {local_file} to {remote_file_path}")
finally:
# Close the SFTP session and SSH transport
sftp.close()
transport.close()
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2024-01-13, 11:12
Aktuell benötige ich Funktionen, um mit Python Dateien von SFTP Servern zu holen bzw. Dateien auf diese hochzuladen. Chat GPT hatte folgenden Code für mich, der sehr gut funktioniert.
import os
import paramiko
# Replace these variables with your specific values
host = '192.168.0.238'
port = 22
username = '<user>'
private_key_path = '<keyfile>'
remote_directory_path = '/home/uwe/downloadtest'
local_directory_path = 'E:/downloadtest'
# Establish SSH connection
try:
# Create a new SSH client
ssh_client = paramiko.SSHClient()
# Automatically add the server's host key
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# Load the private key for authentication
private_key = paramiko.RSAKey.from_private_key_file(private_key_path)
# Connect to the server
ssh_client.connect(hostname=host, port=port, username=username, pkey=private_key)
# Open an SFTP session on the SSH connection
sftp = ssh_client.open_sftp()
# Change to the remote directory
sftp.chdir(remote_directory_path)
# List all files in the remote directory
files = sftp.listdir()
# Download each CSV file in the remote directory
for file_name in files:
# os path join uses system slashes, must make sure they are right
remote_file_path = os.path.join(remote_directory_path, file_name).replace("\\","/")
local_file_path = os.path.join(local_directory_path, file_name).replace("\\","/")
print(remote_file_path, local_file_path)
# Check if the file is a CSV file
if file_name.lower().endswith('.txt'):
sftp.get(remote_file_path, local_file_path)
print(f"File '{file_name}' downloaded successfully to '{local_directory_path}'")
# Close the SFTP session and SSH connection
sftp.close()
ssh_client.close()
except paramiko.AuthenticationException:
print("Authentication failed. Please check your credentials or SSH key path.")
except paramiko.SSHException as e:
print(f"SSH connection failed: {e}")
except FileNotFoundError:
print("File not found. Please provide the correct file paths.")
except Exception as e:
print(f"An error occurred: {e}") |
import os
import paramiko
# Replace these variables with your specific values
host = '192.168.0.238'
port = 22
username = '<user>'
private_key_path = '<keyfile>'
remote_directory_path = '/home/uwe/downloadtest'
local_directory_path = 'E:/downloadtest'
# Establish SSH connection
try:
# Create a new SSH client
ssh_client = paramiko.SSHClient()
# Automatically add the server's host key
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# Load the private key for authentication
private_key = paramiko.RSAKey.from_private_key_file(private_key_path)
# Connect to the server
ssh_client.connect(hostname=host, port=port, username=username, pkey=private_key)
# Open an SFTP session on the SSH connection
sftp = ssh_client.open_sftp()
# Change to the remote directory
sftp.chdir(remote_directory_path)
# List all files in the remote directory
files = sftp.listdir()
# Download each CSV file in the remote directory
for file_name in files:
# os path join uses system slashes, must make sure they are right
remote_file_path = os.path.join(remote_directory_path, file_name).replace("\\","/")
local_file_path = os.path.join(local_directory_path, file_name).replace("\\","/")
print(remote_file_path, local_file_path)
# Check if the file is a CSV file
if file_name.lower().endswith('.txt'):
sftp.get(remote_file_path, local_file_path)
print(f"File '{file_name}' downloaded successfully to '{local_directory_path}'")
# Close the SFTP session and SSH connection
sftp.close()
ssh_client.close()
except paramiko.AuthenticationException:
print("Authentication failed. Please check your credentials or SSH key path.")
except paramiko.SSHException as e:
print(f"SSH connection failed: {e}")
except FileNotFoundError:
print("File not found. Please provide the correct file paths.")
except Exception as e:
print(f"An error occurred: {e}")
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2024-01-13, 11:08
Aktuell benötige ich Funktionalitäten in Python, um E-Mails automatisch versenden zu lassen. Über Chat-GPT habe ich mir passenden Code basteln lassen, der recht gut funktioniert.
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_email():
# Email content
sender_email = 'YOUR_EMAIL_ADDRESS'
password = 'YOUR_PASSWORD'
recipient_email = 'RECIPIENT_EMAIL_ADDRESS'
subject = 'SUBJECT'
body = 'EMAIL_BODY'
# Create a multipart message and set headers
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
# Add body to email
message.attach(MIMEText(body, 'plain'))
try:
# Connect to SMTP server (for Gmail use 'smtp.gmail.com', for others, refer to your provider's settings)
smtp_server = smtplib.SMTP('smtp.yourprovider.com', 587)
smtp_server.starttls() # Enable encryption for security
smtp_server.login(sender_email, password)
# Send email
smtp_server.sendmail(sender_email, recipient_email, message.as_string())
print("Email sent successfully!")
# Close the connection
smtp_server.quit()
except Exception as e:
print(f"Error: {e}")
print("Email was not sent.")
# Call the function to send the email
send_email() |
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_email():
# Email content
sender_email = 'YOUR_EMAIL_ADDRESS'
password = 'YOUR_PASSWORD'
recipient_email = 'RECIPIENT_EMAIL_ADDRESS'
subject = 'SUBJECT'
body = 'EMAIL_BODY'
# Create a multipart message and set headers
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
# Add body to email
message.attach(MIMEText(body, 'plain'))
try:
# Connect to SMTP server (for Gmail use 'smtp.gmail.com', for others, refer to your provider's settings)
smtp_server = smtplib.SMTP('smtp.yourprovider.com', 587)
smtp_server.starttls() # Enable encryption for security
smtp_server.login(sender_email, password)
# Send email
smtp_server.sendmail(sender_email, recipient_email, message.as_string())
print("Email sent successfully!")
# Close the connection
smtp_server.quit()
except Exception as e:
print(f"Error: {e}")
print("Email was not sent.")
# Call the function to send the email
send_email()
Falls der SMTP-Server keine Authentifizierung braucht, dann reicht auch das folgende
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_email():
# Email content
sender_email = 'YOUR_EMAIL_ADDRESS'
recipient_email = 'RECIPIENT_EMAIL_ADDRESS'
subject = 'SUBJECT'
body = 'EMAIL_BODY'
# Create a multipart message and set headers
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
# Add body to email
message.attach(MIMEText(body, 'plain'))
try:
# Connect to SMTP server
smtp_server = smtplib.SMTP('smtp.yourprovider.com') # Replace with your SMTP server address
smtp_server.sendmail(sender_email, recipient_email, message.as_string())
print("Email sent successfully!")
# Close the connection
smtp_server.quit()
except Exception as e:
print(f"Error: {e}")
print("Email was not sent.")
# Call the function to send the email
send_email() |
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_email():
# Email content
sender_email = 'YOUR_EMAIL_ADDRESS'
recipient_email = 'RECIPIENT_EMAIL_ADDRESS'
subject = 'SUBJECT'
body = 'EMAIL_BODY'
# Create a multipart message and set headers
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
# Add body to email
message.attach(MIMEText(body, 'plain'))
try:
# Connect to SMTP server
smtp_server = smtplib.SMTP('smtp.yourprovider.com') # Replace with your SMTP server address
smtp_server.sendmail(sender_email, recipient_email, message.as_string())
print("Email sent successfully!")
# Close the connection
smtp_server.quit()
except Exception as e:
print(f"Error: {e}")
print("Email was not sent.")
# Call the function to send the email
send_email()
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2022-12-25, 22:38
Vor kurzem bin ich gefragt worden, wie man mit jinja2 Umlaute rendern kann. Grundsätzlich hatte ich auch angenommen, dass dies wegen Unicode und so kein Problem sein kann, konnte aber das aufgetretene Problem „öäüÖÜÄ,“ nachstellen.
Die Lösung war dann die folgende:
from jinja2 import Environment, BaseLoader
myString = 'öäü{{hello}}'
template = Environment(loader=BaseLoader).from_string(myString)
with open('render2.tex','wb') as output:
x = template.render(hello='ÖÜÄ')
output.write(x.encode('utf-8')) |
from jinja2 import Environment, BaseLoader
myString = 'öäü{{hello}}'
template = Environment(loader=BaseLoader).from_string(myString)
with open('render2.tex','wb') as output:
x = template.render(hello='ÖÜÄ')
output.write(x.encode('utf-8'))
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2022-12-11, 16:17
Ich bin aktuell dabei, mich mehr in die Anwendungsprogrammierung mit Python einzuarbeiten. Irgendwann läuft es auf ein MVC-Framework hinaus, bis dahin ist erst einmal Experimentieren angesagt. Das folgende Beispiel legt eine SQLite In-Memory Datenbank an, fügt einige Datensätze ein und ändert einen der Datensätze ab. Die Anpassungen werden dabei historisiert über das Validfrom and Validto.
import toml # handle toml files
import sqlite3
from datetime import datetime
import time
settings = toml.load('settings.toml')
dbfilename = settings['dbfilename']
conn = sqlite3.connect(":memory:")
c = conn.cursor()
with conn:
c.execute(
"""
create table if not exists
contacts (id integer primary key,
personid integer,
validfrom text,
validto text,
firstname text,
lastname text,
phonenumber text);
"""
)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
c.execute(f"INSERT INTO contacts (personid, validfrom, validto, firstname, lastname, phonenumber) values (1,'{now}','9999-12-31 23:59:59','Mickey','Mouse','0123-456')")
c.execute(f"INSERT INTO contacts (personid, validfrom, validto, firstname, lastname, phonenumber) values (2,'{now}','9999-12-31 23:59:59','Donald','Duck','0123-123')")
time.sleep(6)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
c.execute(f"UPDATE contacts set validto = '{now}' where id = 1")
time.sleep(6)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
c.execute(f"INSERT INTO contacts (personid, validfrom,validto, firstname, lastname, phonenumber) values (1, '{now}','9999-12-31 23:59:59','Mickey','Mouse','0123-789')")
result = c.execute(f"select * from contacts where validto > '2023-12-31';").fetchall()
for row in result:
print(row) |
import toml # handle toml files
import sqlite3
from datetime import datetime
import time
settings = toml.load('settings.toml')
dbfilename = settings['dbfilename']
conn = sqlite3.connect(":memory:")
c = conn.cursor()
with conn:
c.execute(
"""
create table if not exists
contacts (id integer primary key,
personid integer,
validfrom text,
validto text,
firstname text,
lastname text,
phonenumber text);
"""
)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
c.execute(f"INSERT INTO contacts (personid, validfrom, validto, firstname, lastname, phonenumber) values (1,'{now}','9999-12-31 23:59:59','Mickey','Mouse','0123-456')")
c.execute(f"INSERT INTO contacts (personid, validfrom, validto, firstname, lastname, phonenumber) values (2,'{now}','9999-12-31 23:59:59','Donald','Duck','0123-123')")
time.sleep(6)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
c.execute(f"UPDATE contacts set validto = '{now}' where id = 1")
time.sleep(6)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
c.execute(f"INSERT INTO contacts (personid, validfrom,validto, firstname, lastname, phonenumber) values (1, '{now}','9999-12-31 23:59:59','Mickey','Mouse','0123-789')")
result = c.execute(f"select * from contacts where validto > '2023-12-31';").fetchall()
for row in result:
print(row)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2022-07-09, 18:47
Der folgende Trick hat mir einige Klimmzüge erspart. In einer Textdatei gab es an diversen Stellen mehrfache Leerzeichen, die ich durch ein einzelnes ersetzen wollte.
Ich hätte jetzt einfach so lange doppelte Leerzeichen durch ein einzelnes ersetzen können, bis keine doppelten Leerzeichen mehr vorhanden sind, über einen regular expression geht es aber viel eleganter.
import re
s = 'a b c'
print(re.sub('\s+',' ',s)) |
import re
s = 'a b c'
print(re.sub('\s+',' ',s))
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2022-06-27, 21:02
Ich hatte vor kurzem das Problem (oder die „Challenge“), einen sehr komplexen Cognos-Report anpassen zu müssen. In mehreren dutzend Formeln mussten Formeln angepasst werden, den Formel-Check zur Prüfung meiner Anpassungen konnte ich jedoch nicht nutzen, da die Datenüberprüfung unendlich lang gedauert hätte (schlechtes Report-Design…).
Mit Python gab es aber eine einfache und elegante Lösung, die mit dem Export des Report-Designs in eine XML-Datei begann.
In der XML-Datei fanden sich dann Schnipsel wie
<expression>abs(total((if ([Database].[storedProc].[ColumnID]=6) then ([Database].[storedProc].[Amount]) else (0))))</expression>
Mit dem folgenden Programm-Code konnte ich dann innerhalb der expression-Tags einfach die öffnenden und schließenden Klammern zählen. Wenn die Zahl der öffnenden Klammern nicht der Zahl der schließenden Klammern entsprach, war die Formel noch falsch.
import re
buffer = open('./Report.xml','r').read()
results = re.findall(r"(<expression>)(.*)(</expression>)",buffer,re.MULTILINE)
for result in results:
expression = result[1]
opened = expression.count('(')
closed = expression.count(')')
if opened != closed:
print(expression) |
import re
buffer = open('./Report.xml','r').read()
results = re.findall(r"(<expression>)(.*)(</expression>)",buffer,re.MULTILINE)
for result in results:
expression = result[1]
opened = expression.count('(')
closed = expression.count(')')
if opened != closed:
print(expression)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2022-06-27, 20:47
Nehmen wir mal an, wir haben eine Excel-Datei Daten.xlsx mit Namen, in der es Fehleingaben durch beispielsweise einen Buchstabendreher geben kann:
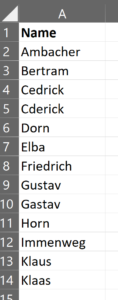
Mit Python und dem Levenshtein-Paket können wir die Ähnlichkeit der Namen recht einfach prüfen.
import pandas as pd
import Levenshtein
df = pd.read_excel('Daten.xlsx')
df = df.sort_values(by=['Name'])
df = df.reset_index(drop=True)
dfs= df.shift() # Shift df by one row
dfs = dfs.rename(columns={'Name': 'Nameshifted'})
df_combined = pd.concat([df,dfs],axis=1) # combine original and shifted df
df_combined = df_combined.fillna('') # remove NaNs
for index, row in df_combined.iterrows():
df_combined.loc[index,'Ratio'] = (Levenshtein.ratio(row['Name'], row['Nameshifted']))
df_combined.loc[index,'Distance'] = (Levenshtein.distance(row['Name'], row['Nameshifted']))
print(df_combined) |
import pandas as pd
import Levenshtein
df = pd.read_excel('Daten.xlsx')
df = df.sort_values(by=['Name'])
df = df.reset_index(drop=True)
dfs= df.shift() # Shift df by one row
dfs = dfs.rename(columns={'Name': 'Nameshifted'})
df_combined = pd.concat([df,dfs],axis=1) # combine original and shifted df
df_combined = df_combined.fillna('') # remove NaNs
for index, row in df_combined.iterrows():
df_combined.loc[index,'Ratio'] = (Levenshtein.ratio(row['Name'], row['Nameshifted']))
df_combined.loc[index,'Distance'] = (Levenshtein.distance(row['Name'], row['Nameshifted']))
print(df_combined)
Als Ergebnis erhält man dann einen Dataframe, der die sortierten Namen miteinander vergleicht und die Levenshtein-Ratio sowie die Levenshtein-Distanz ausgibt.
|
Name |
Nameshifted |
Ratio |
Distance |
| 0 |
Ambacher |
|
0.000000 |
8.0 |
| 1 |
Bertram |
Ambacher |
0.266667 |
8.0 |
| 2 |
Cderick |
Bertram |
0.285714 |
6.0 |
| 3 |
Cedrick |
Cderick |
0.857143 |
2.0 |
| 4 |
Dorn |
Cedrick |
0.181818 |
6.0 |
| 5 |
Elba |
Dorn |
0.000000 |
4.0 |
| 6 |
Friedrich |
Elba |
0.000000 |
9.0 |
| 7 |
Gastav |
Friedrich |
0.000000 |
9.0 |
| 8 |
Gustav |
Gastav |
0.833333 |
1.0 |
| 9 |
Horn |
Gustav |
0.000000 |
6.0 |
| 10 |
Immenweg |
Horn |
0.166667 |
7.0 |
| 11 |
Klaas |
Immenweg |
0.000000 |
8.0 |
| 12 |
Klaus |
Klaas |
0.800000 |
1.0 |
Bei hoher Ratio oder kleiner Distanz sollte man sich die Werte anschauen.
Hinweis: Ich bin hier davon ausgegangen, dass nur im Namen der nächsten Zeile ein Dreher auftreten kann. Vergleicht man alle n Namen mit allen anderen n-1 Namen, so wird es schnell aufwändig und zeitintensiv.
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website