import pandas as pd
import numpy as np
from openpyxl import Workbook
from openpyxl.utils.cell import get_column_letter
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.worksheet.table import Table, TableStyleInfo
from openpyxl.styles import Color, PatternFill, Font, Border
from openpyxl.formatting.rule import ColorScaleRule, CellIsRule, FormulaRule, Rule
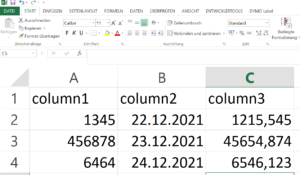
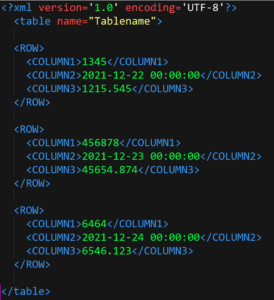
dataframe = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['a', 'b', 'c'])
rows = dataframe_to_rows(dataframe, index=False, header=True)
wb = Workbook()
ws = wb.active
for r_idx, row in enumerate(rows, 1):
for c_idx, value in enumerate(row, 1):
ws.cell(row=r_idx, column=c_idx, value=value)
# Set column widths based on title width or fixed number
widths = {}
for column in ws.columns:
if column[0].value is None: # no column header => Fixed with
widths[column[0].column] = 10.5
else: # if column header is present => min width resp. maximum
widths[column[0].column] = max(len(str(column[0].value)) * 1.45, 10.5)
ws.column_dimensions[get_column_letter(column[0].column)].width = widths[column[0].column]
# Insert formatted table from A1 to max column/max row
tab = Table(displayName="MeineTabelle", ref='A1:' + get_column_letter(ws.max_column) + str(ws.max_row))
style = TableStyleInfo(name="TableStyleLight9", showFirstColumn=False,
showLastColumn=False, showRowStripes=True, showColumnStripes=True)
tab.tableStyleInfo = style
ws.add_table(tab)
# conditional formatting
redFill = PatternFill(start_color='EE1111',end_color='EE1111',fill_type='solid')
greenFill = PatternFill(start_color='EE1111',end_color='11EE11',fill_type='solid')
ws.conditional_formatting.add('A2:B'+str(ws.max_row),CellIsRule(operator='equal', formula=[1], stopIfTrue=True, fill=greenFill))
ws.conditional_formatting.add('A2:B'+str(ws.max_row),CellIsRule(operator='notEqual', formula=[1], stopIfTrue=True, fill=redFill))
lightbluefill = PatternFill(start_color='CCCCFF',end_color='CCCCFF',fill_type='solid')
for rowNum in range(2, ws.max_row + 1):
ws.cell(row=rowNum, column=3).fill = lightbluefill
wb.save('07.xlsx')
wb.close() |