2021-05-09, 11:03
Hier ein bisschen Python-Code, um zwei CSV Dateien miteinander zu vergleichen. Die Ergebnisse des spalten- und zeilenweisen Vergleichs werden dann zusammengefasst dargestellt, um schnell einen Überblick zu bekommen, wo eine tiefergehende Analyse notwendig ist.
import sys
import collections
import pandas as pd
from tabulate import tabulate
file1 = pd.read_csv('file1.csv', sep=';', encoding='UTF-8')
file2 = pd.read_csv('file2.csv', sep=';', encoding='UTF-8')
columnnames1 = list(file1)
columnnames2 = list(file2)
if collections.Counter(columnnames1) == collections.Counter(columnnames2):
print ("Number of columns and Names match, Comparison possible...\n\n")
else:
print ("Number of columns and Names are not matching!!! Please check the input!")
sys.exit('Error!')
# add suffixes to distinguish between actual and expected in the merger
file1 = file1.add_suffix('_e') # expected
file2 = file2.add_suffix('_t') # t
# merge them using the given key, use outer join
comparison = pd.merge(file1,file2, how='outer',
left_on=['Key_e'],
right_on=['Key_t'])
# create the columnwise comparison
for col in columnnames1:
comparison[(col + '_c')] = comparison[(col + '_t')] == comparison[(col + '_e')]
# reorder the columns
comparison=comparison.reindex(sorted(comparison.columns),axis=1)
print(tabulate(comparison, tablefmt="pipe", headers="keys"))
# save the result as Excel file
comparison.to_excel('result.xlsx')
# names of the comparison column
check_colnames= [s + '_c' for s in columnnames1]
# initialize an empty dataframe for the log
logdf=pd.DataFrame(index=[True,False])
for column in check_colnames:
t=comparison[column].value_counts() # returns a series
tt=pd.DataFrame(t) # makes a DF out of the series
logdf = logdf.join(tt,how='outer') # join the two dfs
# transpose for better readability
logdf = logdf.transpose()
# Ensure fixed sequence of the columns
logdf=logdf.reindex(sorted(logdf.columns),axis=1)
# write to disk
logdf.to_excel('logfile.xlsx')
# for better viewing on the screen
logdf.fillna('-',inplace=True)
pd.options.display.float_format = '{:,.0f}'.format
print(tabulate(logdf, tablefmt="pipe", headers="keys")) |
import sys
import collections
import pandas as pd
from tabulate import tabulate
file1 = pd.read_csv('file1.csv', sep=';', encoding='UTF-8')
file2 = pd.read_csv('file2.csv', sep=';', encoding='UTF-8')
columnnames1 = list(file1)
columnnames2 = list(file2)
if collections.Counter(columnnames1) == collections.Counter(columnnames2):
print ("Number of columns and Names match, Comparison possible...\n\n")
else:
print ("Number of columns and Names are not matching!!! Please check the input!")
sys.exit('Error!')
# add suffixes to distinguish between actual and expected in the merger
file1 = file1.add_suffix('_e') # expected
file2 = file2.add_suffix('_t') # t
# merge them using the given key, use outer join
comparison = pd.merge(file1,file2, how='outer',
left_on=['Key_e'],
right_on=['Key_t'])
# create the columnwise comparison
for col in columnnames1:
comparison[(col + '_c')] = comparison[(col + '_t')] == comparison[(col + '_e')]
# reorder the columns
comparison=comparison.reindex(sorted(comparison.columns),axis=1)
print(tabulate(comparison, tablefmt="pipe", headers="keys"))
# save the result as Excel file
comparison.to_excel('result.xlsx')
# names of the comparison column
check_colnames= [s + '_c' for s in columnnames1]
# initialize an empty dataframe for the log
logdf=pd.DataFrame(index=[True,False])
for column in check_colnames:
t=comparison[column].value_counts() # returns a series
tt=pd.DataFrame(t) # makes a DF out of the series
logdf = logdf.join(tt,how='outer') # join the two dfs
# transpose for better readability
logdf = logdf.transpose()
# Ensure fixed sequence of the columns
logdf=logdf.reindex(sorted(logdf.columns),axis=1)
# write to disk
logdf.to_excel('logfile.xlsx')
# for better viewing on the screen
logdf.fillna('-',inplace=True)
pd.options.display.float_format = '{:,.0f}'.format
print(tabulate(logdf, tablefmt="pipe", headers="keys"))
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-17, 12:27
Im Beitrag „CSV-Dateien mit speziellen Spaltentrennern in Python laden“ hatte ich gezeigt, wie man mit BS4 Dateien aus Webseiten extrahieren und abspeichern kann, um sie dann in pandas weiterzuverarbeiten. Es geht auch ohne den Umweg der CSV-Datei, wenn man die StringIO Klasse aus dem io Modul nutzt.
Wir laden das Modul und instanziieren dann ein Objekt der Klasse mit dem von BS4 gefundenen Datensatz. Diese Objekt wird dann anstelle des Pfades der CSV-Datei an die pd.read_csv() Funktion übergeben.
import pandas as pd
import requests
from bs4 import BeautifulSoup
from io import StringIO
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
url = "http://www.statistics4u.com/fundstat_eng/data_fluriedw.html"
req = requests.get(url, headers)
soup = BeautifulSoup(req.content, 'html.parser')
data=soup.find('pre').contents[0]
str_object = StringIO(data)
df = pd.read_csv(str_object,engine='python',skiprows=5,delim_whitespace=True)
print(df) |
import pandas as pd
import requests
from bs4 import BeautifulSoup
from io import StringIO
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
url = "http://www.statistics4u.com/fundstat_eng/data_fluriedw.html"
req = requests.get(url, headers)
soup = BeautifulSoup(req.content, 'html.parser')
data=soup.find('pre').contents[0]
str_object = StringIO(data)
df = pd.read_csv(str_object,engine='python',skiprows=5,delim_whitespace=True)
print(df)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2020-12-30, 18:16
Nachdem wir uns im letzten Artikel angeschaut hatten, wie man mit openpyxl Funktionen Felder in CSV-Dateien mit Werten aus Excel-Dateien ersetzen kann, heute nun die pandas Implementierung dessen.
Sie nutzt auch openpyxl zum Einlesen der Excel-Datei, da xlrd, das bisher von pandas genutzte Modul für Excel-Dateien, den Support für XLSX Formate eingestellt hat.
Die Arbeitsweise des Codes ist recht einfach. pandas liest die Datei, da die Tabelle nicht links oben anfängt, werden die erste Zeile und Spalte ignoriert und die Spalten passend benannt. Dann iterieren wird durch den Dataframe und ersetzen munter…
import pandas as pd
path = "python_test.xlsx"
df = pd.read_excel(path,engine='openpyxl',
sheet_name='Tabelle2',skiprows=1,
usecols={1,2},header=None)
df = df.rename(columns={1: "Key", 2: "Value"})
with open('Python_test.txt') as input_file:
text = input_file.read()
for index, row in df.iterrows():
text = text.replace(row['Key'] ,str(row['Value']))
with open('Python_test_output_pd.txt','w') as output_file:
output_file.write(text) |
import pandas as pd
path = "python_test.xlsx"
df = pd.read_excel(path,engine='openpyxl',
sheet_name='Tabelle2',skiprows=1,
usecols={1,2},header=None)
df = df.rename(columns={1: "Key", 2: "Value"})
with open('Python_test.txt') as input_file:
text = input_file.read()
for index, row in df.iterrows():
text = text.replace(row['Key'] ,str(row['Value']))
with open('Python_test_output_pd.txt','w') as output_file:
output_file.write(text)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2020-12-26, 18:46
Nachdem wir bereits mit Excel und VBA Platzhalter in CSV Dateien gesucht und mit Inhalten ersetzt haben heute das ganze mit Python und OpenPyxl.
Ausgangspunkt ist eine Exceldatei „python_test.xlsx“ mit einer Named Range „Felder“ im Tabellenblatt „Tabelle2“.
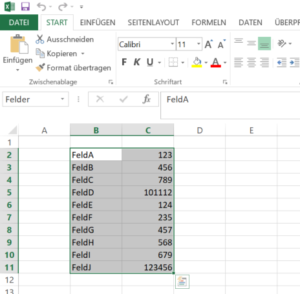
Mit der openpyxl Bibliothek laden wir das Excel-Blatt und holen uns die Inhalte der Range in ein Dictionary. Jeden der Keys aus dem Dictionary suchen wir dann in der CSV Datei und ersetzen ihn gegen den Wert aus der Excel-Datei.
# -*- coding: utf-8 -*-
import openpyxl
path = "python_test.xlsx"
workbook = openpyxl.load_workbook(path)
def get_sheet_and_location(workbook, named_range):
x = list(workbook.defined_names['Felder'].destinations)[0]
return x[0], x[1].replace('$','').split(':')[0],x[1].replace('$','').split(':')[1]
sheet, start, stop = get_sheet_and_location(workbook,'Felder')
worksheet = workbook[sheet]
rng=worksheet[start:stop]
replacements = {}
for row in rng:
c1, c2 = row
replacements[c1.value] = c2.value
with open('Python_test.txt') as input_file:
text = input_file.read()
for key in replacements:
text = text.replace(key,str(replacements[key]))
with open('Python_test_output.txt','w') as output_file:
output_file.write(text) |
# -*- coding: utf-8 -*-
import openpyxl
path = "python_test.xlsx"
workbook = openpyxl.load_workbook(path)
def get_sheet_and_location(workbook, named_range):
x = list(workbook.defined_names['Felder'].destinations)[0]
return x[0], x[1].replace('$','').split(':')[0],x[1].replace('$','').split(':')[1]
sheet, start, stop = get_sheet_and_location(workbook,'Felder')
worksheet = workbook[sheet]
rng=worksheet[start:stop]
replacements = {}
for row in rng:
c1, c2 = row
replacements[c1.value] = c2.value
with open('Python_test.txt') as input_file:
text = input_file.read()
for key in replacements:
text = text.replace(key,str(replacements[key]))
with open('Python_test_output.txt','w') as output_file:
output_file.write(text)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website