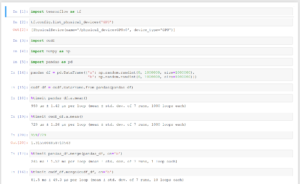
Heute mal mal mit Excel und VBA. Ziel ist es, in einer Textdatei (komma-separiert, Punkt als Dezimalzeichen) Platzhalter durch Werte zu ersetzen, ohne dass die Datei dabei von Excel kaputt „optimiert“ wird.
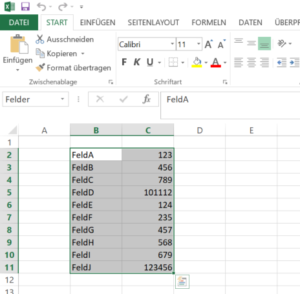
Die Excel-Datei sieht dabei so aus:
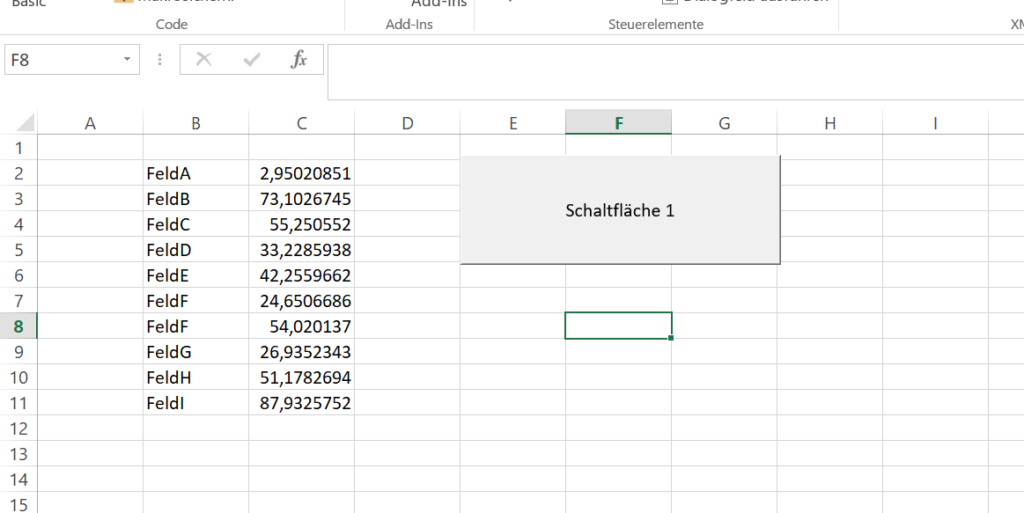
Einfach nur ein paar Werte untereinander, Dezimaltrenner ist das Komma.
CSV-Quelldatei „Quelle.csv“:
SpalteA,SpalteB,SpalteC
FeldA,WertA,1.12
FeldB,WertB,1.23
FeldC,WertC,1.34
FeldD,WertD,1.45
FeldE,WertE,1.56
FeldF,WertF,1.67
FeldG,WertG,1.78
FeldH,WertH,1.89
FeldI,WertI,1.90
FeldJ,WertJ,1.95
Hinter dem Buttom im Excel liegt der folgende VBA/VBS Code, den ich bei http://www.office-loesung.de gefunden und adaptiert habe.
Option Explicit
Sub Schaltfläche1_Klicken()
Dim fso, f, text
Set fso = CreateObject("Scripting.FileSystemObject")
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Quelle.csv", 1)
text = f.ReadAll
text = Replace(text, "WertA", Replace(Cells(2, 3).Value, ",", "."))
text = Replace(text, "WertB", Replace(Cells(3, 3).Value, ",", "."))
text = Replace(text, "WertC", Replace(Cells(4, 3).Value, ",", "."))
text = Replace(text, "WertD", Replace(Cells(5, 3).Value, ",", "."))
text = Replace(text, "WertE", Replace(Cells(6, 3).Value, ",", "."))
text = Replace(text, "WertF", Replace(Cells(7, 3).Value, ",", "."))
text = Replace(text, "WertG", Replace(Cells(8, 3).Value, ",", "."))
text = Replace(text, "WertH", Replace(Cells(9, 3).Value, ",", "."))
text = Replace(text, "WertI", Replace(Cells(10, 3).Value, ",", "."))
f.Close
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Ziel.csv", 2, True)
f.Write (text)
f.Close
End Sub |
Option Explicit
Sub Schaltfläche1_Klicken()
Dim fso, f, text
Set fso = CreateObject("Scripting.FileSystemObject")
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Quelle.csv", 1)
text = f.ReadAll
text = Replace(text, "WertA", Replace(Cells(2, 3).Value, ",", "."))
text = Replace(text, "WertB", Replace(Cells(3, 3).Value, ",", "."))
text = Replace(text, "WertC", Replace(Cells(4, 3).Value, ",", "."))
text = Replace(text, "WertD", Replace(Cells(5, 3).Value, ",", "."))
text = Replace(text, "WertE", Replace(Cells(6, 3).Value, ",", "."))
text = Replace(text, "WertF", Replace(Cells(7, 3).Value, ",", "."))
text = Replace(text, "WertG", Replace(Cells(8, 3).Value, ",", "."))
text = Replace(text, "WertH", Replace(Cells(9, 3).Value, ",", "."))
text = Replace(text, "WertI", Replace(Cells(10, 3).Value, ",", "."))
f.Close
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Ziel.csv", 2, True)
f.Write (text)
f.Close
End Sub
Das Ergebnis „Ziel.csv“ sieht dann so aus:
SpalteA,SpalteB,SpalteC
FeldA,2.9502085126608,1.12
FeldB,73.1026744983578,1.23
FeldC,55.250551974564,1.34
FeldD,33.2285937834519,1.45
FeldE,42.2559662206547,1.56
FeldF,24.6506686140567,1.67
FeldG,54.0201369859298,1.78
FeldH,26.9352342768415,1.89
FeldI,51.1782693678183,1.90
FeldJ,87.9325752371774,1.95
Es geht natürlich noch viel eleganter, indem man zum Beispiel Ranges nutzt, als Proof-of-Concept reicht dies jedoch schon aus.
Mit named Ranges würde die Lösung so aussehen:
Option Explicit
Sub Schaltfläche1_Klicken()
Dim fso, f, text
Set fso = CreateObject("Scripting.FileSystemObject")
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Quelle.csv", 1)
text = f.ReadAll
text = Replace(text, "WertA", Replace(Range("FeldA").Value, ",", "."))
text = Replace(text, "WertB", Replace(Range("FeldB").Value, ",", "."))
text = Replace(text, "WertC", Replace(Range("FeldC").Value, ",", "."))
text = Replace(text, "WertD", Replace(Range("FeldD").Value, ",", "."))
text = Replace(text, "WertE", Replace(Range("FeldE").Value, ",", "."))
text = Replace(text, "WertF", Replace(Range("FeldF").Value, ",", "."))
text = Replace(text, "WertG", Replace(Range("FeldG").Value, ",", "."))
text = Replace(text, "WertH", Replace(Range("FeldH").Value, ",", "."))
text = Replace(text, "WertI", Replace(Range("FeldI").Value, ",", "."))
text = Replace(text, "WertJ", Replace(Range("FeldJ").Value, ",", "."))
f.Close
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Ziel.csv", 2, True)
f.Write (text)
f.Close
End Sub |
Option Explicit
Sub Schaltfläche1_Klicken()
Dim fso, f, text
Set fso = CreateObject("Scripting.FileSystemObject")
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Quelle.csv", 1)
text = f.ReadAll
text = Replace(text, "WertA", Replace(Range("FeldA").Value, ",", "."))
text = Replace(text, "WertB", Replace(Range("FeldB").Value, ",", "."))
text = Replace(text, "WertC", Replace(Range("FeldC").Value, ",", "."))
text = Replace(text, "WertD", Replace(Range("FeldD").Value, ",", "."))
text = Replace(text, "WertE", Replace(Range("FeldE").Value, ",", "."))
text = Replace(text, "WertF", Replace(Range("FeldF").Value, ",", "."))
text = Replace(text, "WertG", Replace(Range("FeldG").Value, ",", "."))
text = Replace(text, "WertH", Replace(Range("FeldH").Value, ",", "."))
text = Replace(text, "WertI", Replace(Range("FeldI").Value, ",", "."))
text = Replace(text, "WertJ", Replace(Range("FeldJ").Value, ",", "."))
f.Close
Set f = fso.OpenTextFile("E:\SearchReplaceVBA\Ziel.csv", 2, True)
f.Write (text)
f.Close
End Sub
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website