Buchungen auswerten mit Python Pandas
Ich bin ehrenamtlich Schatzmeister der Dingfabrik Köln e.V., als solcher muss ich auch schauen, welches Mitglied denn die Beiträge bezahlt hat. Mit Hilfe von Pandas lassen sich die Buchungsdaten sehr elegant aufbereiten.
Ausgangspunkt sind die folgenden Excel-Dateien
Mitglieder.xlsx
Enthält die Mitgliedsnummer, den Namen sowie die Mitgliedsart (F für Fördermitglied, O für Ordentlich, E für Ehemalig, etc.)
| Klasse | Name | Mitgliedsart |
| 1 | Max Mustermann | O |
Buchungen.xlsx
Die Buchungen wurden aus Quicken 2015 nach Excel exportiert, die Datei muss leider noch manuell bearbeitet werden, da der Excel-Export von Quicken nicht sonderlich schön ist. Die relevante Kategorie ist in diesem Beispiel „Mitgliedsbeitrag“, Klasse enthält die zugewiesene Mitgliedsnummer.
| Buchungstag | Konto | Vorgang | Empfänger | Verwendungszweck | Kategorie | Klasse | Betrag |
| 04.01.2016 | Firmengirokonto Köln | 3763 | Buchungstext bla, bla | Mitgliedsbeitrag | 1 | 23,00 |
Diese beiden Dateien können wir jetzt mit Pandas verarbeiten.
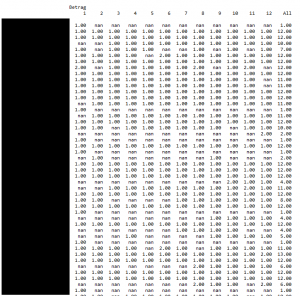
import pandas as pd import numpy as np import time as t # Anpassungen an der Pandas-Ausgabe pd.set_option('display.float_format', lambda x: '%.2f' % x) # http://stackoverflow.com/questions/11707586/python-pandas-widen-output-display pd.set_option('display.height', 1000) pd.set_option('display.max_rows', 500) pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1000) # lies die Stammdaten aus Excel mitglieder = pd.read_excel('Mitglieder.xlsx', 'Tabelle1') # konvertier die Mitgliedsnummer in einen String mitglieder['Klasse'] = mitglieder['Klasse'].apply(int).apply(str) # Ehemalige Mitglieder interessieren nicht mitglieder = mitglieder[mitglieder.Mitgliedsart.str.contains('A|F|O')] # lies die Buchungen ein buchungen = pd.read_excel('Buchungen.xlsx', 'Sheet') # entferne alle Zeilen, die keinen 'Mitgliedbeitrag' enthalten buchungen = buchungen[buchungen.Kategorie.str.contains('Mitgliedsbeitrag')] # entferne Zeilen ohne Betrag oder Klasse buchungen = buchungen[np.isfinite(buchungen['Betrag'])] buchungen = buchungen[np.isfinite(buchungen['Klasse'])] # Konvertiere den Buchungstag in ein Pandas-Datum buchungen['Buchungstag'] = pd.to_datetime(buchungen['Buchungstag'],dayfirst=True,format='%d.%m.%Y') # Füge neue Spalten für Quartal und Monat hinzu buchungen['Quartal'] = buchungen['Buchungstag'].dt.quarter buchungen['Monat'] = buchungen['Buchungstag'].dt.month # Wandle 'Klasse' von Float => Integer => String buchungen['Klasse'] = buchungen['Klasse'].apply(int).apply(str) # Führe einen right join durch, wir wollen auch die Datensätze von Mitgliedern haben, die noch aktiv sind, aber noch nichts bezahlt haben buchungen = pd.merge(buchungen,mitglieder, how='right', on=['Klasse', 'Klasse']) # Durch den right Join haben wir jetzt einige NaN (Not a Number) Zellen, die wir durch 0.0 ersetzen # Dadurch erzeugen wir Dummy Datensätze, die aber nicht stören buchungen['Betrag'].fillna(value=0,inplace=True) buchungen['Buchungstag'].fillna(value=pd.Timestamp('20160101'),inplace=True) # Einen Eintrag für die Monatsspalte nehmen wir auch vor, darüber wird pivotisiert buchungen['Monat'] = buchungen['Buchungstag'].dt.month # Erstellung der Pivot-Table pivotTable = pd.pivot_table(buchungen,dropna=False,margins=True,index=['Name'],values=['Betrag'],columns=['Monat'],aggfunc=np.sum) print(pivotTable) # Optional: Rausschreiben der Tabelle nach Excel #pivotTable.to_excel('pivotisiert.xlsx') |
Das Ergebnis, hier anonymisiert und bei Betrag nur jeweils 1.0 eingetragen, sieht dann so aus: