Archive for the ‘Python / SciPy / pandas’ Category.
2021-01-17, 12:27
Im Beitrag „CSV-Dateien mit speziellen Spaltentrennern in Python laden“ hatte ich gezeigt, wie man mit BS4 Dateien aus Webseiten extrahieren und abspeichern kann, um sie dann in pandas weiterzuverarbeiten. Es geht auch ohne den Umweg der CSV-Datei, wenn man die StringIO Klasse aus dem io Modul nutzt.
Wir laden das Modul und instanziieren dann ein Objekt der Klasse mit dem von BS4 gefundenen Datensatz. Diese Objekt wird dann anstelle des Pfades der CSV-Datei an die pd.read_csv() Funktion übergeben.
import pandas as pd
import requests
from bs4 import BeautifulSoup
from io import StringIO
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
url = "http://www.statistics4u.com/fundstat_eng/data_fluriedw.html"
req = requests.get(url, headers)
soup = BeautifulSoup(req.content, 'html.parser')
data=soup.find('pre').contents[0]
str_object = StringIO(data)
df = pd.read_csv(str_object,engine='python',skiprows=5,delim_whitespace=True)
print(df) |
import pandas as pd
import requests
from bs4 import BeautifulSoup
from io import StringIO
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
url = "http://www.statistics4u.com/fundstat_eng/data_fluriedw.html"
req = requests.get(url, headers)
soup = BeautifulSoup(req.content, 'html.parser')
data=soup.find('pre').contents[0]
str_object = StringIO(data)
df = pd.read_csv(str_object,engine='python',skiprows=5,delim_whitespace=True)
print(df)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-17, 11:58
Hier ein Beispiel, wie man Bilder für eine Animation mit matplotlib erstellen kann, adaptiert von im Netz gefundenen Code
Der folgende Python-Code erzeugt 720 einzelne Bilder und legt diese im Dateisystem ab. Mittels magick -quality 100 *.png outputfile.mpeg werden dann die Bilder zu einem MPEG-Video kombiniert. Hinweis: Nur unter Windows heißt der Befehl „magick“ da „convert“ auch ein Systemprogramm ist.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
df = sns.load_dataset('iris')
sns.set(style = "darkgrid")
fig = plt.figure()
fig.set_size_inches(16, 9)
ax = fig.add_subplot(111, projection = '3d')
x = df['sepal_width']
y = df['sepal_length']
z = df['petal_width']
ax.set_xlabel("sepal_width")
ax.set_ylabel("sepal_lesngth")
ax.set_zlabel("petal_width")
c = {'setosa':'red', 'versicolor':'blue', 'virginica':'green'}
ax.scatter(x, y, z,c=df['species'].apply(lambda x: c[x]))
for angle in range(0, 720):
ax.view_init((angle+1)/10, angle)
plt.draw()
plt.savefig('r:/'+str(angle).zfill(3)+'.png')
Eine kürzere Version der Animation habe ich unter https://www.youtube.com/watch?v=gdgvXpq4k1w abgelegt.
Hinweise zu anderen Konvertierungsprogrammen gibt es unter anderem hier: https://www.andrewnoske.com/wiki/Convert_an_image_sequence_to_a_movie
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-17, 00:21
Um einige Klassifikations-Algorithmen in Python ausprobieren zu können habe ich heute die Swiss Banknote Data von Flury und Riedwyl benötigt. Die Daten sind im Netz z.B. unter http://www.statistics4u.com/fundstat_eng/data_fluriedw.html verfügbar, ich wollte sie aber nicht manuell einladen müssen.
Mit dem folgenden Code, adaptiert von https://hackersandslackers.com/scraping-urls-with-beautifulsoup/, kann man die Daten lokal abspeichern und dann in einen pandas Dataframe einladen.
import pandas as pd
import requests
from bs4 import BeautifulSoup
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
url = "http://www.statistics4u.com/fundstat_eng/data_fluriedw.html"
req = requests.get(url, headers)
soup = BeautifulSoup(req.content, 'html.parser')
a=soup.find('pre').contents[0]
with open('banknote.csv','wt') as data:
data.write(a)
df = pd.read_csv('banknote.csv',engine='python',skiprows=5,delim_whitespace=True)
print(df) |
import pandas as pd
import requests
from bs4 import BeautifulSoup
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
url = "http://www.statistics4u.com/fundstat_eng/data_fluriedw.html"
req = requests.get(url, headers)
soup = BeautifulSoup(req.content, 'html.parser')
a=soup.find('pre').contents[0]
with open('banknote.csv','wt') as data:
data.write(a)
df = pd.read_csv('banknote.csv',engine='python',skiprows=5,delim_whitespace=True)
print(df)
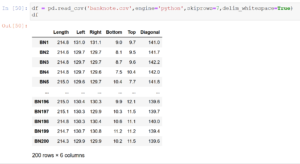
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-16, 20:49
Ich habe heute auf einer meiner Linux-Maschinen Jupyter Notebook installiert. Um die — für die Arbeit im lokalen Netz lästigen — Sicherheitsabfragen zu umgehen, habe ich mir ausgehend von https://stackoverflow.com/questions/41159797/how-to-disable-password-request-for-a-jupyter-notebook-session ein kleines Startskript geschrieben:
#! /bin/bash
jupyter notebook --ip='*' --NotebookApp.token='' --NotebookApp.password='' |
#! /bin/bash
jupyter notebook --ip='*' --NotebookApp.token='' --NotebookApp.password=''
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-16, 20:45
Mit cudf gibt es ein Paket, das pandas Datenstrukturen auf nvidia-Grafikkarten verarbeiten kann. Einen i7 3770 mit 24 GB RAM habe ich jetzt mit einer CUDA-fähigen Grafikkarte (Typ Quadro P400) ausgestattet, damit ich damit rumspielen arbeiten kann. Unter https://towardsdatascience.com/heres-how-you-can-speedup-pandas-with-cudf-and-gpus-9ddc1716d5f2 findet man passende Beispiele, diese habe ich in einem Jupyter-Notebook laufenlassen.
Ein Geschwindigkeitszuwachs ist erkennbar, insbesondere bei der Matrix-Größe aus dem verlinkten Beispiel war die CUDA-Variante mehr als 3x so schnell wie die CPU-Variante. Das Merge mit der vollen Matrix-Größe lief bei mir leider nicht, da limitieren vermutlich die 2 GB RAM, die die P400 bietet.
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-10, 19:19
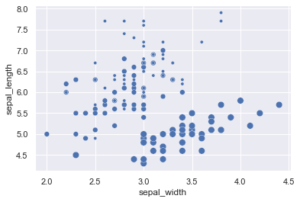
Im letzten Beitrag hatten wir mit hue die Zugehörigkeit der Iris Data Orchideen dargestellt, Seaborn besitzt aber mit style und size noch weitere Möglichkeiten der Unterscheidung. style nutzt dabei verschiedene Symbole, size unterschiedliche Punktgrößen. Die verschiedenen Optionen können auch kombiniert werden.
import seaborn as sns
sns.set(style = "darkgrid")
iris=sns.load_dataset('iris')
sns.scatterplot(
x=iris['sepal_width'],
y=iris['sepal_length'],
style=iris['species'],
legend=False
) |
import seaborn as sns
sns.set(style = "darkgrid")
iris=sns.load_dataset('iris')
sns.scatterplot(
x=iris['sepal_width'],
y=iris['sepal_length'],
style=iris['species'],
legend=False
)
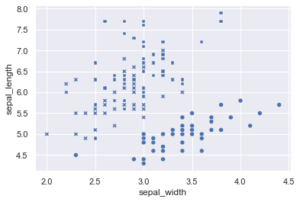
import seaborn as sns
sns.set(style = "darkgrid")
iris=sns.load_dataset('iris')
sns.scatterplot(
x=iris['sepal_width'],
y=iris['sepal_length'],
size=iris['species'],
legend=False
) |
import seaborn as sns
sns.set(style = "darkgrid")
iris=sns.load_dataset('iris')
sns.scatterplot(
x=iris['sepal_width'],
y=iris['sepal_length'],
size=iris['species'],
legend=False
)
import seaborn as sns
sns.set(style = "darkgrid")
iris=sns.load_dataset('iris')
sns.scatterplot(
x=iris['sepal_width'],
y=iris['sepal_length'],
hue=iris['species'],
style=iris['species'],
size=iris['species'],
legend=False
) |
import seaborn as sns
sns.set(style = "darkgrid")
iris=sns.load_dataset('iris')
sns.scatterplot(
x=iris['sepal_width'],
y=iris['sepal_length'],
hue=iris['species'],
style=iris['species'],
size=iris['species'],
legend=False
)
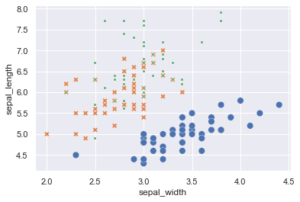
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2021-01-09, 20:37
Hier ein einfaches Beispiel für einen Scatterplot mit Python und dem Seaborn Modul. Das Beispiel nutzt den bekannten Iris-Datensatz von R. Fisher, der gut für Klassifikationstechniken genutzt werden kann.
import seaborn as sns
iris=sns.load_dataset('iris')
sns.scatterplot(x=iris['sepal_width'],y=iris['sepal_length'],hue=iris['species']) |
import seaborn as sns
iris=sns.load_dataset('iris')
sns.scatterplot(x=iris['sepal_width'],y=iris['sepal_length'],hue=iris['species'])
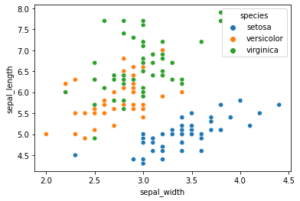
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2020-12-30, 18:16
Nachdem wir uns im letzten Artikel angeschaut hatten, wie man mit openpyxl Funktionen Felder in CSV-Dateien mit Werten aus Excel-Dateien ersetzen kann, heute nun die pandas Implementierung dessen.
Sie nutzt auch openpyxl zum Einlesen der Excel-Datei, da xlrd, das bisher von pandas genutzte Modul für Excel-Dateien, den Support für XLSX Formate eingestellt hat.
Die Arbeitsweise des Codes ist recht einfach. pandas liest die Datei, da die Tabelle nicht links oben anfängt, werden die erste Zeile und Spalte ignoriert und die Spalten passend benannt. Dann iterieren wird durch den Dataframe und ersetzen munter…
import pandas as pd
path = "python_test.xlsx"
df = pd.read_excel(path,engine='openpyxl',
sheet_name='Tabelle2',skiprows=1,
usecols={1,2},header=None)
df = df.rename(columns={1: "Key", 2: "Value"})
with open('Python_test.txt') as input_file:
text = input_file.read()
for index, row in df.iterrows():
text = text.replace(row['Key'] ,str(row['Value']))
with open('Python_test_output_pd.txt','w') as output_file:
output_file.write(text) |
import pandas as pd
path = "python_test.xlsx"
df = pd.read_excel(path,engine='openpyxl',
sheet_name='Tabelle2',skiprows=1,
usecols={1,2},header=None)
df = df.rename(columns={1: "Key", 2: "Value"})
with open('Python_test.txt') as input_file:
text = input_file.read()
for index, row in df.iterrows():
text = text.replace(row['Key'] ,str(row['Value']))
with open('Python_test_output_pd.txt','w') as output_file:
output_file.write(text)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2020-12-26, 18:46
Nachdem wir bereits mit Excel und VBA Platzhalter in CSV Dateien gesucht und mit Inhalten ersetzt haben heute das ganze mit Python und OpenPyxl.
Ausgangspunkt ist eine Exceldatei „python_test.xlsx“ mit einer Named Range „Felder“ im Tabellenblatt „Tabelle2“.
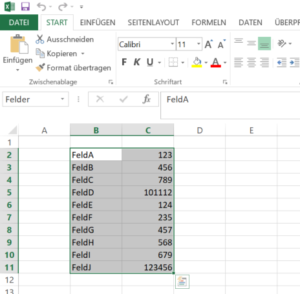
Mit der openpyxl Bibliothek laden wir das Excel-Blatt und holen uns die Inhalte der Range in ein Dictionary. Jeden der Keys aus dem Dictionary suchen wir dann in der CSV Datei und ersetzen ihn gegen den Wert aus der Excel-Datei.
# -*- coding: utf-8 -*-
import openpyxl
path = "python_test.xlsx"
workbook = openpyxl.load_workbook(path)
def get_sheet_and_location(workbook, named_range):
x = list(workbook.defined_names['Felder'].destinations)[0]
return x[0], x[1].replace('$','').split(':')[0],x[1].replace('$','').split(':')[1]
sheet, start, stop = get_sheet_and_location(workbook,'Felder')
worksheet = workbook[sheet]
rng=worksheet[start:stop]
replacements = {}
for row in rng:
c1, c2 = row
replacements[c1.value] = c2.value
with open('Python_test.txt') as input_file:
text = input_file.read()
for key in replacements:
text = text.replace(key,str(replacements[key]))
with open('Python_test_output.txt','w') as output_file:
output_file.write(text) |
# -*- coding: utf-8 -*-
import openpyxl
path = "python_test.xlsx"
workbook = openpyxl.load_workbook(path)
def get_sheet_and_location(workbook, named_range):
x = list(workbook.defined_names['Felder'].destinations)[0]
return x[0], x[1].replace('$','').split(':')[0],x[1].replace('$','').split(':')[1]
sheet, start, stop = get_sheet_and_location(workbook,'Felder')
worksheet = workbook[sheet]
rng=worksheet[start:stop]
replacements = {}
for row in rng:
c1, c2 = row
replacements[c1.value] = c2.value
with open('Python_test.txt') as input_file:
text = input_file.read()
for key in replacements:
text = text.replace(key,str(replacements[key]))
with open('Python_test_output.txt','w') as output_file:
output_file.write(text)
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website
2020-10-25, 07:43
Ausgehend von meinem ersten Artikel zu diesem Thema habe ich jetzt noch eine Erweiterung des Skripts vorgenommen. Als Spammer erkannte E-Mail-Adressen werden jetzt auch automatisch geblockt.
Dazu suche ich alle „Dauerhaft von der Liste verbannen“ Checkboxen — ihre Namen beginnen alle mit „ban-“ — und klicke sie.
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.common.exceptions import NoSuchElementException
opts = Options()
browser = Firefox(executable_path=r"C:\geckodriver-v0.27.0\geckodriver.exe",
options=opts)
browser.implicitly_wait(3)
browser.get('<url>')
search_form = browser.find_element_by_name('adminpw')
search_form.send_keys('<password>')
search_form.submit()
try:
field = browser.find_element_by_name('discardalldefersp')
field.click()
browser.implicitly_wait(3)
submit = browser.find_element_by_name('submit')
submit.click()
except NoSuchElementException:
print('No new messages to be discarded')
browser.implicitly_wait(3)
fields = browser.find_elements_by_xpath("//input[@value='3']")
emails = browser.find_elements_by_xpath('//td[contains(text(),"@")]')
banfields = browser.find_elements_by_xpath('//input[contains(@name,"ban-")]')
if len(fields) == 0:
print('No new requests to be discarded, closing browser')
browser.close()
else:
if len(fields) == len(emails) and len(fields) == len(banfields) :
zipped_list = list(zip(emails, fields, banfields))
for i in zipped_list:
email, field, banfield = i
if not email.text.endswith(')'):
field.click()
banfield.click() |
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.common.exceptions import NoSuchElementException
opts = Options()
browser = Firefox(executable_path=r"C:\geckodriver-v0.27.0\geckodriver.exe",
options=opts)
browser.implicitly_wait(3)
browser.get('<url>')
search_form = browser.find_element_by_name('adminpw')
search_form.send_keys('<password>')
search_form.submit()
try:
field = browser.find_element_by_name('discardalldefersp')
field.click()
browser.implicitly_wait(3)
submit = browser.find_element_by_name('submit')
submit.click()
except NoSuchElementException:
print('No new messages to be discarded')
browser.implicitly_wait(3)
fields = browser.find_elements_by_xpath("//input[@value='3']")
emails = browser.find_elements_by_xpath('//td[contains(text(),"@")]')
banfields = browser.find_elements_by_xpath('//input[contains(@name,"ban-")]')
if len(fields) == 0:
print('No new requests to be discarded, closing browser')
browser.close()
else:
if len(fields) == len(emails) and len(fields) == len(banfields) :
zipped_list = list(zip(emails, fields, banfields))
for i in zipped_list:
email, field, banfield = i
if not email.text.endswith(')'):
field.click()
banfield.click()
Uwe Ziegenhagen likes LaTeX and Python, sometimes even combined.
Do you like my content and would like to thank me for it? Consider making a small donation to my local fablab, the Dingfabrik Köln. Details on how to donate can be found here Spenden für die Dingfabrik.
More Posts - Website